Beginners Guide to System Design Diagrams
Demystify the world of system design with our insightful blog, offering in-depth knowledge on constructing intuitive system design diagrams for optimal communication.
Functional Requirements
The process of system design begins with defining the functional requirements of a software system. In a system like Instagram, you would consider features such as:
- Uploading images
- Making posts
- Follow other users
- Liking other users' posts
The list could be quite extensive. However, for a student learning system design, a subset of features like these can provide a good starting point.
In reality, though, defining functional requirements requires in-depth discussions with product managers. These systems range from payment systems, insurance claims, or credit reporting applications.
Non-Functional Requirements
Non-functional requirements typically define the scale of a system. They provide information about the number of users and their activities, like writing, uploading images, or reading content. These requirements also aid in determining the necessary resources for building the system.
Availability
Non-functional requirements also encompass factors like acceptable downtime. This is where the discussion of "2 nines" (99.99%) versus "3 nines" (99.999%) availability arises. The design of our system will vary considerably based on these requirements.
Speed
You can also address the speed of the application as part of non-functional requirements. This involves deciding how fast web pages should load or the acceptable web service response time.
Estimation
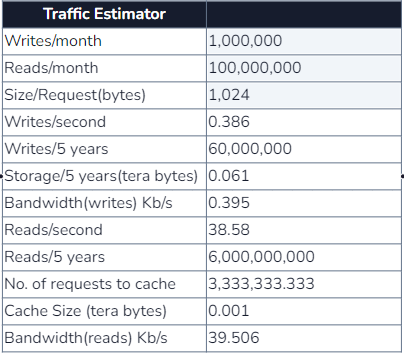
Storage
To calculate the storage required for the system, we estimate the number of users and their actions. If each picture has a size of 5 MB and we upload 10 pictures daily, the storage usage will be 50 MB per day. If there are 100 users, the total storage needed per day would be 100 users x 50 MB = 500 MB.
Bandwidth
Similarly, we can calculate the required bandwidth for the system. The number of writes per second multiplied by the size of each write determines the bandwidth.
Cache
As a general rule, the cache size should be around 20% of the storage required per day.
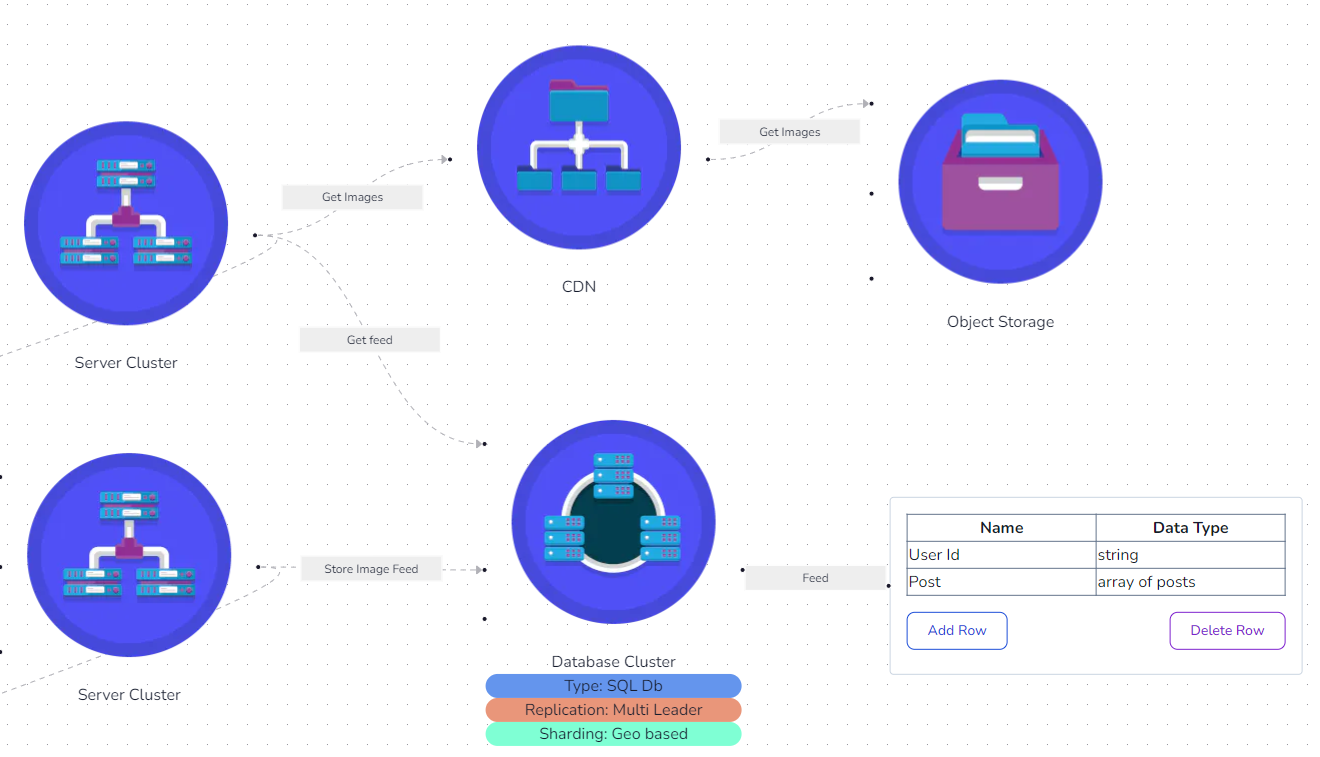
API Design
Now it is time to start considering the necessary API calls for the client system. Tasks like adding a picture or getting an Instagram feed are API calls we can think about when designing the system.
Compute
An API request typically interacts with a compute resource that defines the business logic of the API. In some cases, the API may pass through an API gateway, load balancer, or both, depending on the design. For load balancers, we need to design how to distribute incoming traffic. Is a simple round-robin approach sufficient, or do we require a more sophisticated algorithm? In the past, computer resources were servers. Operating systems such as Windows or Linux ran these servers. They used web server software like Apache or IIS. Nowadays, people often use virtual machines or containers running in the cloud for computing.
Database
Types
Databases nowadays are broadly divided into SQL databases and NoSQL databases. Traditionally, databases have been SQL databases, which store structured data, therefore the tables had dependencies on each other. However, these data dependencies made scaling much harder.
Vertical scaling, which involves increasing the size of a single database, has its limitations. With horizontal scaling, we spin up multiple database servers as the next option.
Scaling horizontally is more challenging with regular SQL databases because of the data dependencies. This led to the rise of NoSQL databases, which store unstructured data and enable easier horizontal scaling.
Other types of databases include key-value, wide column, and graph databases.
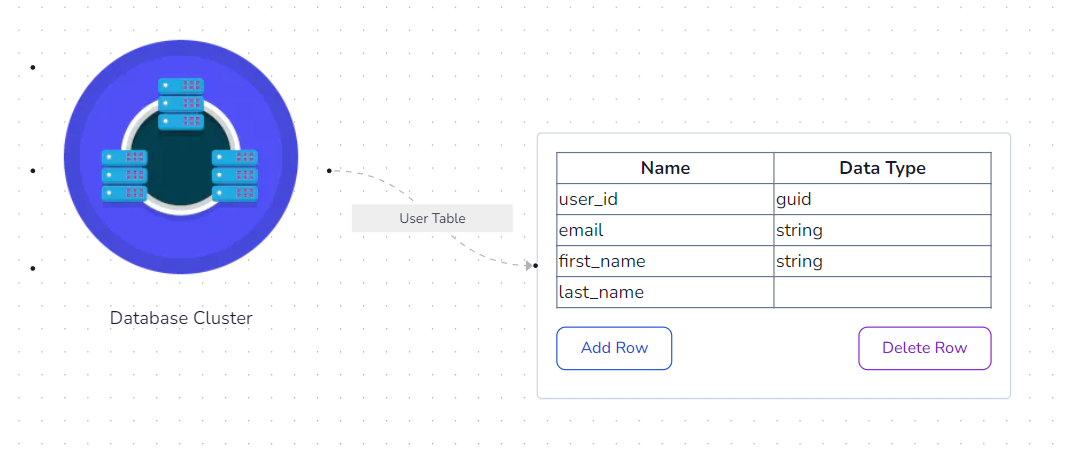
Table Design
Table design is also a part of system design. Table design includes determining the type and the format of data that needs to be stored. For example, a User table may include fields such as user ID, first name, last name, and email.
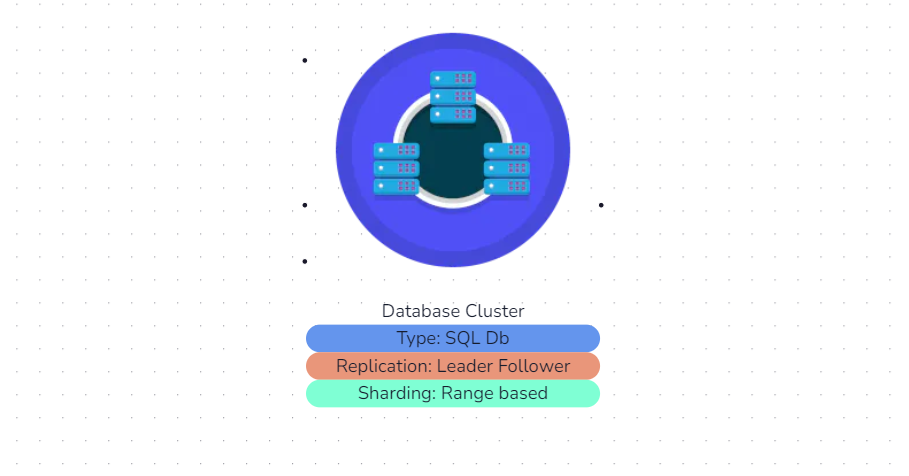
Replication
Databases cannot rely on a single source for all data. If a database server fails, it could result in data loss. This is why replication is important.
If there is a data loss, you can recover it from a backup database that replicates it. Replication can also help distribute the load on a single database. For busy databases, read queries go to the copied database, and write queries go to the main database.
Various strategies for replicating a database include leader-follower, multileader, and leader-less replication.
Sharding
In situations where there is a large amount of data, even a simple query can be slow. Sharding is a concept that involves data partitioning and identifying it with a key.
For example, users can shard data based on user ID, with odd users stored in one shard and even users stored in another. By doing this, the database server only needs to examine half the data when running a query.
Some well-known sharding methods include geo-based sharding, hash-based sharding, and range-based sharding.
Caching
A cache is a high-speed data store that designers can use at various stages of system design. One common use case is to have a cache between a database and a compute server. The cache in a data-intensive system, such as one that retrieves the top 10 popular products, stores information. This allows the compute server to avoid constantly querying the database.
Eviction
The cache is typically an expensive memory and therefore a limited resource. We need to decide how much data to store and what data to store in it. Should we store the most frequently accessed data or the most recently used data? This decision depends on the specific system being designed.
Population
A cache can be populated using several techniques. If the server doesn't have the data in the cache, it retrieves it from the database. This will then add the data to the cache for future use. Alternatively, you can actively populate the data, ensuring that it is always available in the cache.
CDN
Content Delivery Network (CDN) is a network of computers that hosts static content like images, CSS, and JavaScript files. CDN is supported by a server that hosts all the original content. CDNs cache content requests around the globe when a user requests content from the server. This enables the fast delivery of content around the globe.
Message Queues
The message queue facilitates asynchronous processing of computing requests. In a high transaction system, message queues enable processing according to the capacity of the system without losing transactions. If you have thousands of requests hitting the server system it can run out of capacity and start dropping requests. However, when a message queue is placed in front of a server, it can help streamline the requests to the server so they can all be processed.
Get Updates
Sign up and receive the latest updates via email.